Because of incomplete observability, machine learning is often associated with uncertainty and stochastic quantities – hence, probably with sampled data.
In spite of the fact that we have little data and don’t know the entire population, we want to make reliable conclusions about the behavior of a random variable.
The sampled data can be generalized to the population, so we must estimate the real underlying data-generation process.

We can compute the probability of a particular outcome by accounting for the results’ variability by understanding the probability distribution. It allows us to generalize from samples to populations, to estimate the function that generates data, and to predict more accurately the behavior of random variables.



A Bernoulli distribution is a discrete probability distribution for the value of a binary random variable, which has either a value of 1 or 0. It is named after Swiss mathematician Jacob Bernoulli.
It can be thought of as a model that provides the set of possible outcomes for a single experiment, and it can be answered with a simple yes or no question.
In more formal terms, this function is expressed by the following equation

This equation essentially evaluates to p if k=1 or to (1-p) if k=0. There is only one parameter associated with the Bernoulli distribution, p.
Consider tossing a fair coin once. A probability of getting heads of coin is equal to 0.5. We see the following plot when visualizing the PMF:

In a series of n independent trials, each with a binary result, a binomial distribution describes the discrete probability distribution of the number of successes. The likelihood of success or failure is expressed by probability p or (1-p).
In this way, we can parametrize the binomial distribution by the parameters
n∈ N , p ∈ [0,1]
To express a binomial distribution with more formal terms, we can use the following equation:
![]()
Success of k is determined by p to the power of k, whereas failure is determined by (1-p) to the power of n minus k, which is simply the number of trials minus the one during which we obtain k.
We have “n choose k” ways to distribute the success k in n trials since success can occur anywhere in n trials.
Take our coin-tossing example from before as an example and let’s expand on it.
To begin, we’ll flip the fair coin three times, while keeping an eye on the random variable that describes the number of heads that are obtained.
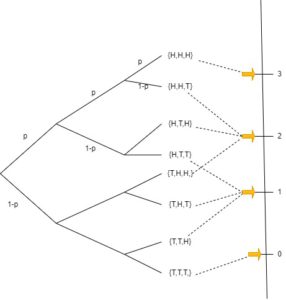
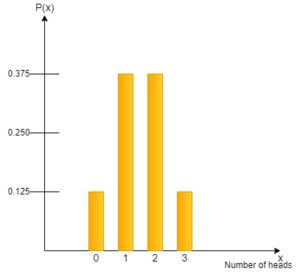
We can simply use the equation from before in order to compute the probability of the coin coming up head twice.

This results in a probability P(2) = 0.375. We obtain the following distribution if we follow the same process for the remaining probabilities:

As you learned in the earlier sections, random variables are either discrete or continuous. A probability mass function can be used to describe the probability distribution if it is discrete.
As we are dealing with continuous variables, a probability density function (PDF) is appropriate for describing the probability distribution.
PDFs do not directly indicate the probability of a random variable taking a specific state, as the PMF does. Rather, it represents the probability of landing within an infinitesimal area. Another way to put it is the PDF indicates the likelihood of a random variable lying between a certain range of values.
In order to determine the actual probability mass, we must integrate, which yields the area above the x-axis but beneath the density function.

There must be no negative values in the probability density function and the integral should be 1.

In probability theory, the gaussian distribution or normal distribution is one of the most common continuous distributions.
In situations where a real-valued random variable whose distribution is unknown, the Gaussian distribution is often considered a reasonable choice.
There is a main reason for this due to the central limit theorem, which states that the average of many independent random variables with finite mean and variance can be seen as a random variable in itself – one with a normal distribution as the number of observations increases.
The advantage of this is that complex systems can be modeled as Gaussian distributed even when their individual components have more complex structural characteristics or distributions.
This is also due to the fact that it inserts the least amount of prior knowledge into the equation when modeling a continuous variable.
Gaussian distribution is expressed formally as
![]()
Here the parameter µ represents the mean, whileσ²describes the variance.
A bell-shaped distribution’s peak will be defined by its mean, while its width will be determined by its variance or standard deviation.
Normal distributions are illustrated as follows:



